
GPT 5.4 Mini vs. Flash 3, which model actually picks the right coding context?
A real production benchmark on auto-context selection, comparing speed, cost, and file-picking quality before the main coding step between gpt 5.4 mini and google gemini flash 3

TL;DR: Flash 3 picks better coding context than GPT-5.4 Mini on medium tasks; Mini-High narrows the gap.
In our production coding workflow, we use the LISP model:
Lens ➜ Index ➜ Select ➜ Perform
Lens (globs) ➜ Human defines what the model can see
Index (code-map) ➜ AI maps the lensed material, for each file: summary, when to use, public types, public functions
Select (auto-context) ➜ AI picks the relevant files for the prompt
Perform (main work) ➜ AI executes with precise context
The auto-context stage takes the user request plus project-level summaries and decides which files the final coding model should receive. That decision has a direct impact on output quality. If the wrong files are selected, the downstream coding step starts with the wrong context, or with too much context, even if the execution model itself is strong.
Note: AIPack v0.8.20 has been released with the new GPT 5.4 mini/nano aliases and updated pricing info. Release note: https://substack.com/@jeremychone/note/c-230413138
The test
We ran a real auto-context selection task for production coding.
The model gets:
A code map file for each source path, with summary, when_to_use, public_types, and public_functions
The user prompt
An instruction to select the appropriate paths for that prompt
In this case, the available file set is about 70 files and 8k LOC, so it is relatively small.
This is not an extreme retrieval problem. It is a medium-complexity selection task, the kind of step many coding agents and developer workflows need to get right consistently.
Test setup
We ran the same auto-context task across several model settings:
minimini-mediummini-highflash
Each run used the same prompt, the same code map, and the same context files.
The goal was simple: measure the tradeoff between speed, cost, and selection quality for a real auto-context step in a production coding workflow.
The config with pro@coder is as follows:
context_globs:
- "*.*"
- src/**/*.*
- doc/**/*.*
- dev/spec/*.*
- tests/**/*.*
- "!tests/.out/**/*.*"
auto_context:
model: mini-medium
input_concurrency: 32
dev:
chat: true
plan: false
model: mini
And the prompt is:
Do not write any code file, just read and update dev chat.
tell me what is missing on the new doc for llm. We added quite a bit the last few weeks.
We changed auto_context.model across mini, mini-medium, mini-high, and flash, cleaning the dev chat for each iteration.
Results
Here are the results for the task, from worst to best:
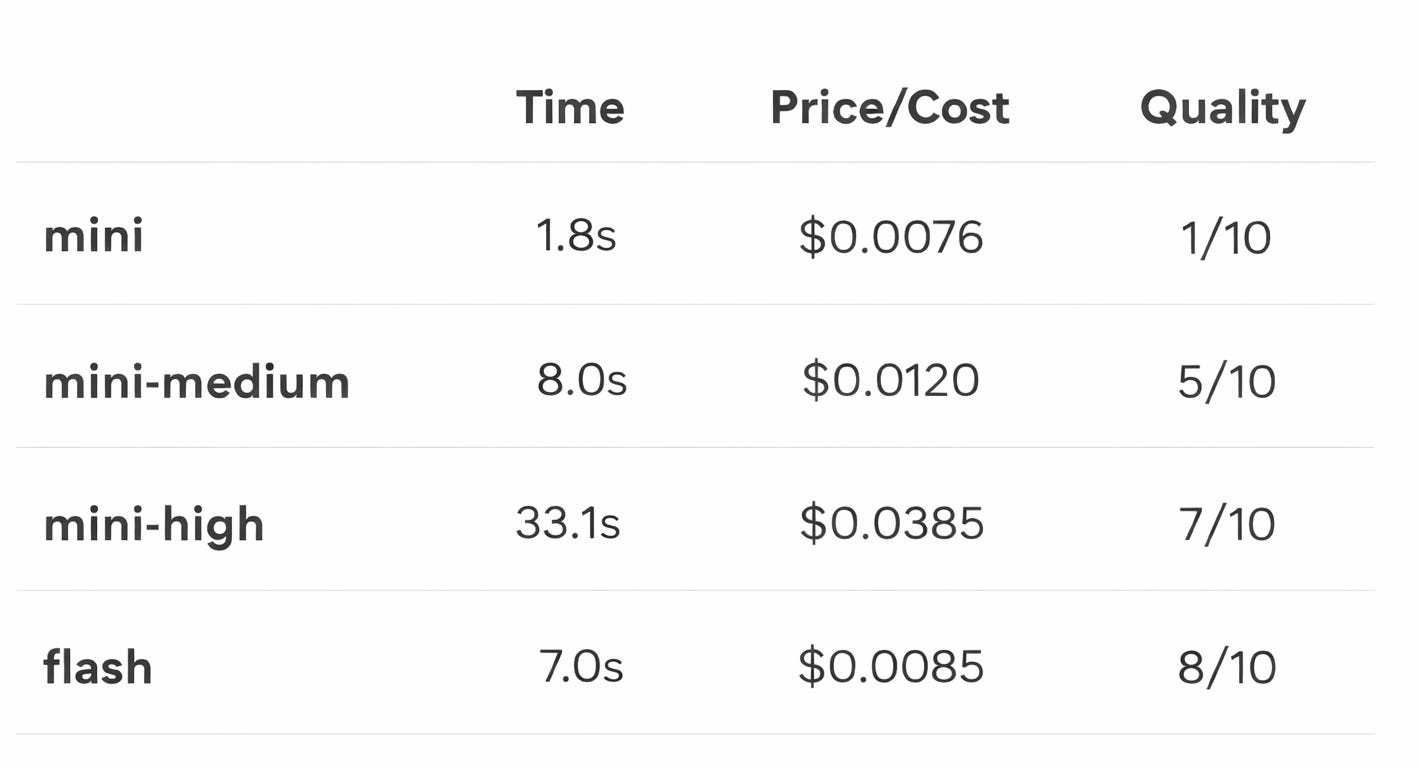
Note: This is based on a few runs for this particular use case. In practice, medium-complexity tasks like this can still provide a useful relative benchmark.
What the test shows
For this specific auto-context task:
flashproduced the best overall resultminiwas extremely fast, but the quality was too low for this taskmini-mediumimproved onmini, but was still not reliable enoughmini-highgot much closer on quality, but with a significant latency cost
The quality gap shows up quickly on this kind of medium-complexity context selection task.
Practical takeaway
If your workflow depends on selecting the right files before the main coding step, this is the kind of benchmark worth tracking.
Auto-context is one of those places where a small quality gap can create a much larger downstream problem. A model that is fast but selects the wrong files does not really save time.
In this test, flash gave the best balance for the task.
We will keep running more variations on the same benchmark and share the results.